Task Description
This task aims to evaluate the capability of an automatic system for Chinese dimensional ABSA. This task can be further divided into three subtasks described as follows.
Subtask 1: Intensity Prediction
The first subtask focuses on predicting sentiment intensities in the valence-arousal dimensions. Given a sentence and a specific aspect, the system should predict the valence-arousal ratings. The input format consists of ID, sentence, and aspect. The output format consists of the ID and valence-arousal predicted values that are separated with a 'space'. The intensity prediction is two real-valued scores rounded to two decimal places and separated by a hashtag, each denotes the valence and arousal rating, respectively.
Example 1
(Traditional Chinese version)
Input: E0001:S001, 檸檬醬也不會太油,塔皮對我而言稍軟。, 檸檬醬#塔皮
Output: E0001:S001 (檸檬醬,5.67#5.5)(塔皮,4.83#5.0)
(Simplified Chinese version)
Input: E0001:S001, 柠檬酱也不会太油,塔皮对我而言稍软。 柠檬酱#塔皮
Output: E0001:S001 (柠檬酱,5.67#5.5)(塔皮,4.83#5.0)
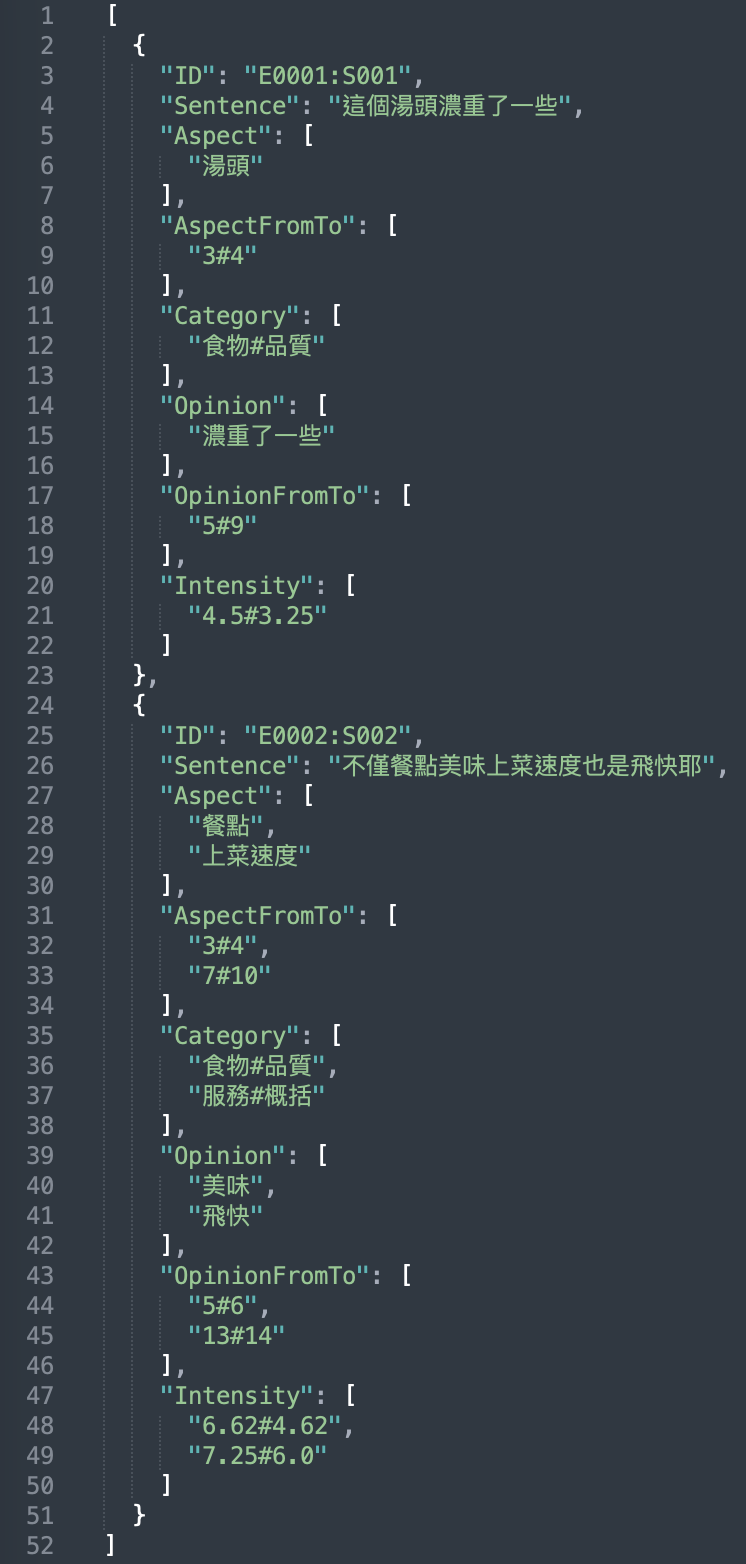
Subtask 2: Triplet Extraction
The second subtask aims to extract sentiment triplets composed of three elements. Given a sentence only, the system should extract all sentiment triplets (aspect, opinion, intensity). The output format consists of the ID and sentiment triplet that are separated with a 'space'.
Example 2
(Traditional Chinese version)
Input: E0002:S002, 不僅餐點美味上菜速度也是飛快耶!!
Output: E0002:S002 (餐點, 美味, 6.63#4.63) (上菜速度, 飛快, 7.25#6.00)
(Simplified Chinese version)
Input: E0002:S002, 不仅餐点美味上菜速度也是飞快耶!!
Output: E0002:S002 (餐点, 美味, 6.63#4.63) (上菜速度, 飞快, 7.25#6.00)
Subtask 3: Quadruple Extraction
The third subtask aims to extract sentiment quadruples composed of four elements. Given a sentence only, the system should extract all sentiment quadruples (aspect, category, opinion, intensity). The output format consists of the ID and sentiment quadruple that are separated with a 'space'.
Example 3
(Traditional Chinese version)
Input: E0003:S003, 這碗拉麵超級無敵霹靂難吃
Output: E0003:S003 (拉麵, 食物#品質, 超級無敵霹靂難吃, 2.00#7.88)
(Simplified Chinese version)
Input: E0003:S003, 这碗拉面超级无敌霹雳难吃
Output: E0003:S003 (拉面, 食物#品质, 超级无敌霹雳难吃, 2.00#7.88)